型別的大影響
- 發布日期
除了記憶體用量之外,型別有什麼作用?當我在解 Special Sequence這個 ZeroJudge 問題時, 我發現了沒有使用優化的古怪行為。
前輟和
這個問題很簡單:找到一個子陣列,其和可被整除且起始點與結束點都是最小的。母陣列可以長達 100000 元素。由於檢測時會大量使用到陣列和, 我們可以使用前輟和,對陣列而言,其前輟和是,這代表 ,可用來在常數時間內找到陣列和。 由於我們在找的是可被整除這件事,我們可以檢查, 又由於我們可以提前算後者,且是較小的型別,理論上來說,後者括號中的數值可以被自動隱晦轉型成和一樣小的型別, 這樣速度就快許多了。於是,我寫了這個解:
#include <stdio.h>
// prefix sum (from i = 1)
long long int sum[100001] = {0};
long long int mods[100001];
int solve()
{
size_t n;
int k;
scanf("%zu", &n);
if (!n)
return 0;
for (size_t i = 1; i <= n; i++)
{
int x;
scanf("%d", &x);
sum[i] = sum[i - 1] + x;
}
scanf("%d", &k);
for (size_t i = 0; i <= n; i++)
{
mods[i] = sum[i] % k;
}
// sum[b] - sum[a] = [a+1, b]
for (size_t i = 0; i < n; i++)
{
for (size_t j = i + 1; j <= n; j++)
{
if ((mods[j] - mods[i]) % k == 0) // (sum[j] - sum[i]) % k = (sum[j] % k - sum[i] % k) % k
{
printf("%zu %zu\n", i + 1, j);
return 1;
}
}
}
printf("no solutions.\n");
return 1;
}
int main()
{
while (solve())
;
return 0;
}
不過,結果是 TLE(超時錯誤),還不知道兇手是誰。
WYSIWYG
所看等於所得
透過編譯器探索器,我潛入了背後的組合語言深淵。
由於 ZeroJudge 不優化程式碼,我將編譯器參數留空。結果我發現(mods[j] - mods[i]) % k根本沒有被轉型。產生了使用QWORD的idiv指令,
比預期的DWORD慢一些。因此,我將原程式碼修改成這樣。
-long long int mods[100001];
+int mods[100001];
現在它使用DWORD,水喔!
測試分析
為了證明我的臆測,我使用下列程式碼分析所花時間,每個測驗皆是 100000 個取模運算。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX_TESTS 100
#define MAX_UNITS 100000
#define GET_TIME(x, dt) \
{ \
clock_t begin, end; \
begin = clock(); \
x; \
end = clock(); \
dt = (double)(end - begin) / CLOCKS_PER_SEC; \
}
long long int buffer[MAX_UNITS];
int main()
{
srand(time(NULL));
for (size_t i = 0; i < MAX_UNITS; i++)
{
buffer[i] = (long long int)(((float)rand() / (float)RAND_MAX) * 10000.0f);
}
int k = 57;
double sm = 0;
int a = 0;
for (unsigned int iter = 0; iter < MAX_TESTS; iter++)
{
double dt;
GET_TIME(
for (size_t i = 0; i < MAX_UNITS; i++) {
if ((unsigned long long int)buffer[i] % k == 0)
{
++a;
}
},
dt)
sm += dt;
}
double avg = sm / (double)MAX_TESTS;
printf("unsigned long long int: %f sec\n", avg);
sm = 0.0;
for (unsigned int iter = 0; iter < MAX_TESTS; iter++)
{
double dt;
GET_TIME(
for (size_t i = 0; i < MAX_UNITS; i++) {
if ((unsigned int)buffer[i] % k == 0)
{
++a;
}
},
dt)
sm += dt;
}
avg = sm / (double)MAX_TESTS;
printf("unsigned int: %f sec\n", avg);
sm = 0.0;
for (unsigned int iter = 0; iter < MAX_TESTS; iter++)
{
double dt;
GET_TIME(
for (size_t i = 0; i < MAX_UNITS; i++) {
if ((long long int)buffer[i] % k == 0)
{
++a;
}
},
dt)
sm += dt;
}
avg = sm / (double)MAX_TESTS;
printf("long long int: %f sec\n", avg);
sm = 0.0;
for (unsigned int iter = 0; iter < MAX_TESTS; iter++)
{
double dt;
GET_TIME(
for (size_t i = 0; i < MAX_UNITS; i++) {
if ((int)buffer[i] % k == 0)
{
++a;
}
},
dt)
sm += dt;
}
avg = sm / (double)MAX_TESTS;
printf("int: %f sec\n", avg);
sm = 0.0;
return 0;
}
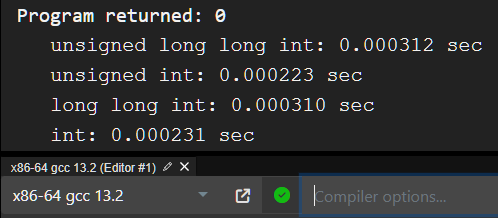
我是對的,它們確實在未優化的情況下花了不同多的時間。如果我們將上表採納入分析中,最糟的情況是秒, 其中是上表中對應到的型別的時間,的係數是 49999.5,大到可以決定是否會 TLE。
型別很重要
當你在使用低階程式語言時,請注意使用的型別,當你在開發攸關效率的應用程式,它們可以積累效率上的問題。